In this article I’ll be briefly looking into the theory of how GIT works. It’s actually quite simple but when you’re starting out it can be very puzzling. I will assume you already know a little bit of what GIT does and what it is for, so this is not a tutorial. No commands here.
What GIT is in essence
GIT is essentially a file system, with the ability to store all of a file’s change history. Here’s how GIT compares to a regular file system.
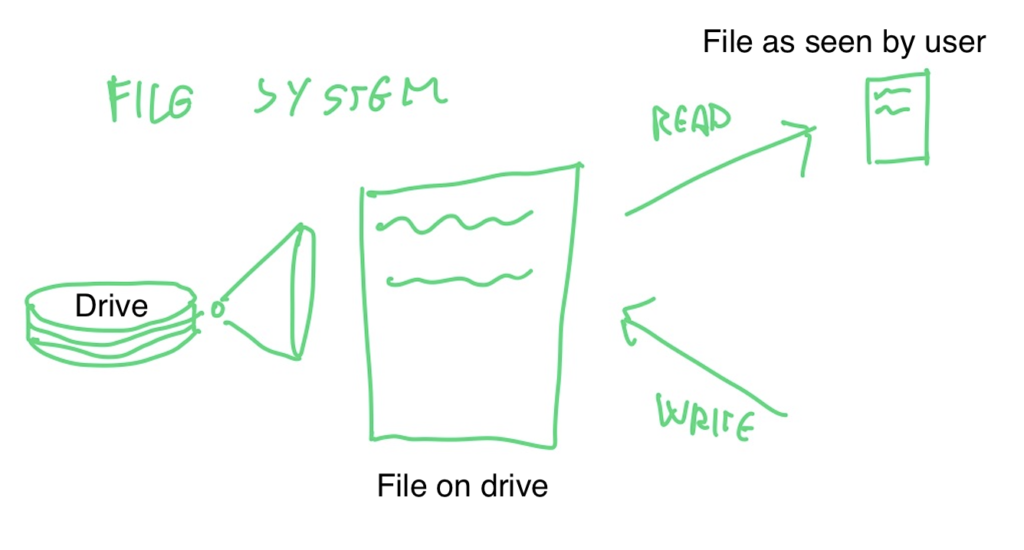
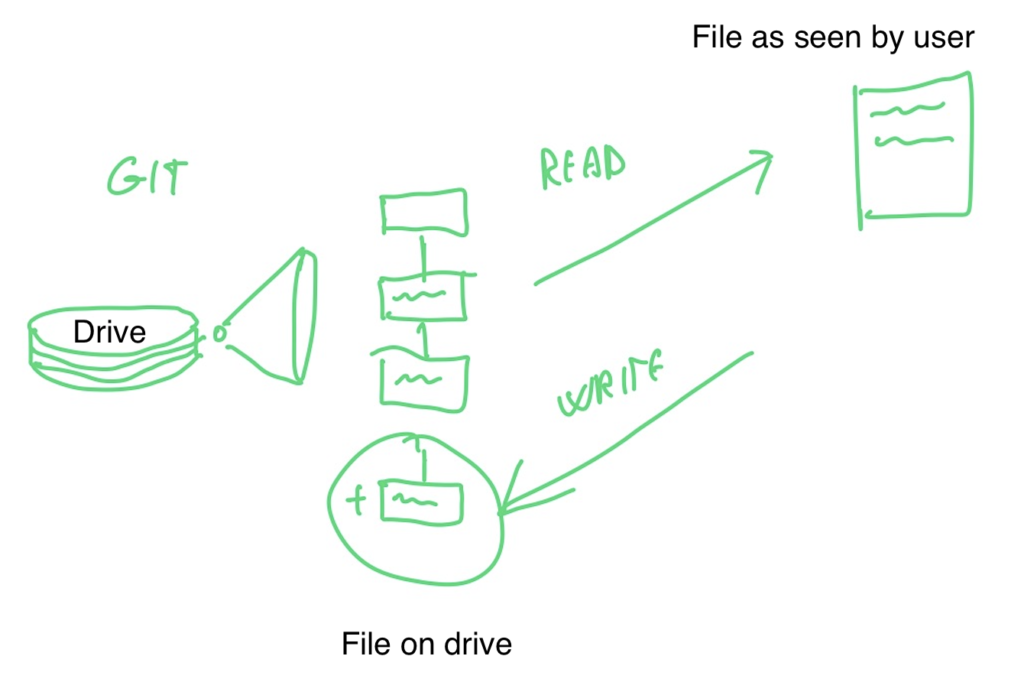
What you see is that on git, the file is not actually stored, what is stored instead is the initial file and a chain of changes to the initial file.
Commits
Here’s what making a change does to a regular file system and to git.
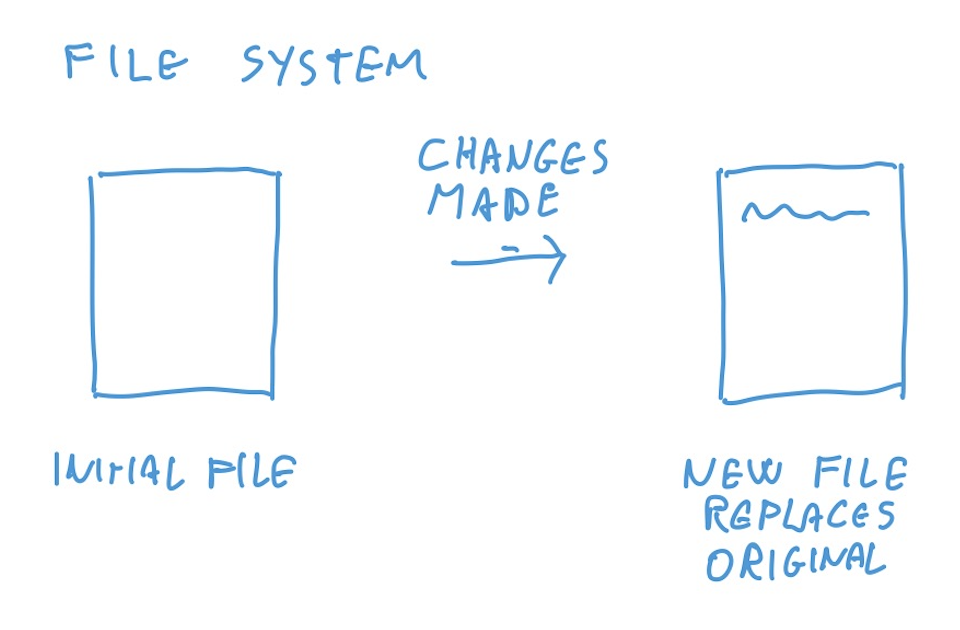
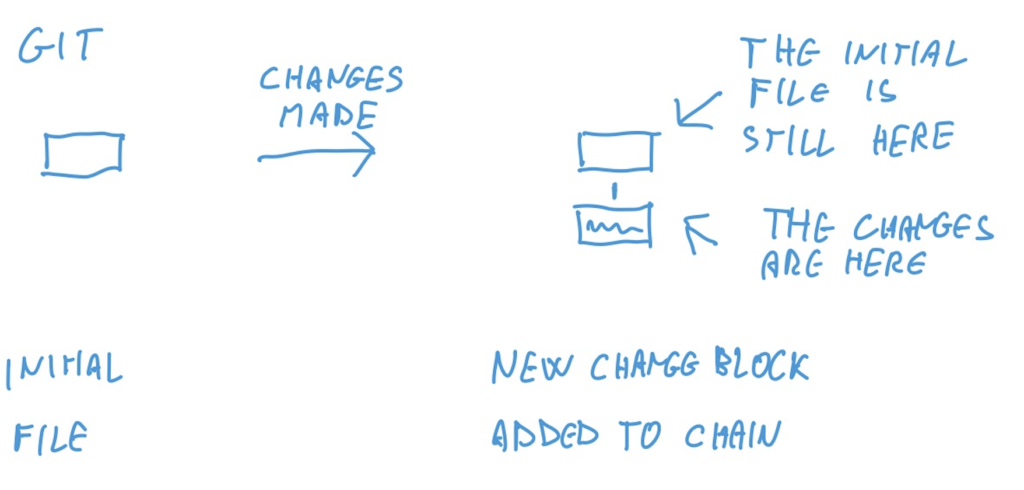
So this is the first core concept of git, the concept of a commit. A commit is the “change block” you see in the picture.
A commit is made by 2 things: a reference to the previous commit (the one the changes should be applied to) and a set of changes to apply to it.
Whenever you want to make a change in git, you need to make a commit!
Branches
Because the change history is essentially a chain of commits, it is possible for the chain to fork.
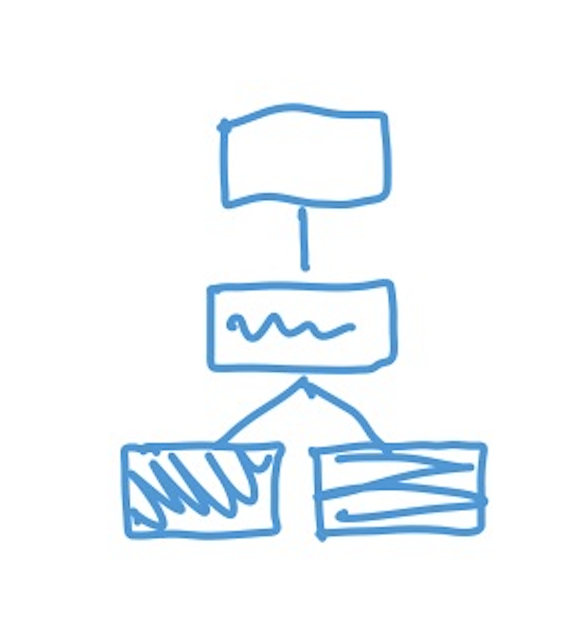
The picture above shows a commit chain forking in two at the end. So how can you know which of the two ends is the correct one? Well simply there isn’t a correct one, those are two different versions of the same file. So you can put a name on each, and you can do that with a branch.
A branch is just a pointer to a commit. It’s a way to put a name on a commit. Really it is a bit more than that because a branch will follow commits added to it, in other words, if you add a commit to a branch, the branch will update to point to the new commit.
Conclusion
I will write another post about how merging branches works and tags and a few other concepts.
For now that’s all, I hope you liked it! If you did, you should consider signing up to my newsletter!